1. 알림 시스템 설계
1.1 개요
알림 시스템은 많은 서비스에서 최신 뉴스, 제품 업데이트, 이벤트 등 비즈니스적으로 중요한 내용을 비동기로 제공한다. 모바일 푸시, SMS, 그리고 이메일로 분류할 수 있다
1.2 기본 설계
1) IOS

- 알림 제공자 : 알림 요청을 만들어 애플 푸시 알림 서비스로 보내는 주체. 알림 요청을 보내려면 device token, payload 데이터가 필요하다
- 알림 서비스(APNS) : 애플에서 제공하는 원격 서비스. 푸시 알림을 IOS 장치로 보내는 역할을 담당한다
2) AOS : APNS 대신 FCM을 사용한다(기본 설계는 같다)
3) 이메일, SMS 역시 동일
4) 연락처 정보 수집 절차

- 알림을 보내려면 모바일 단말 토큰, 전화번호, 이메일 주소 등의 정보가 필요
- 앱을 설치한 후 계정 가입 시 사용자 정보를 DB에 저장
5) 설계 2차
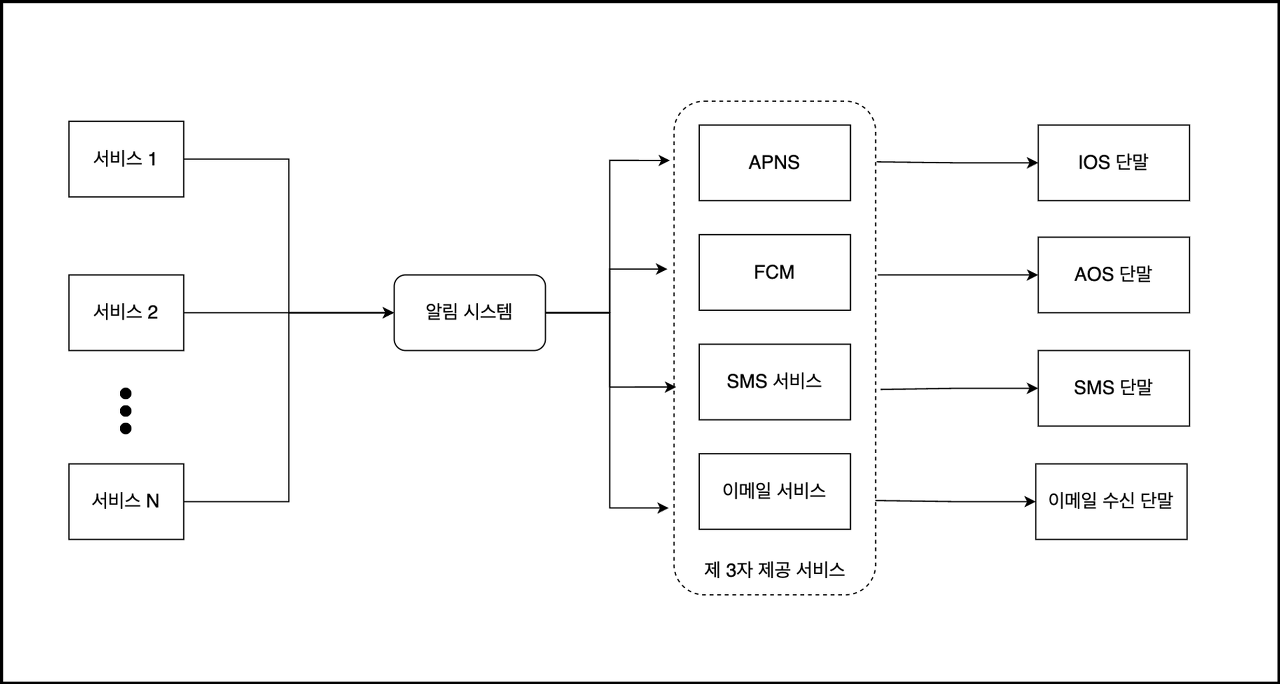
5-1) N개의 서비스 : 각각 마이크로서비스, 크론잡, 분산 시스템 컴포넌트일 수 있다
5-2) 알림 시스템 : 시스템은 서비스 1번부터 N번까지 알림 전송을 위한 API를 제공해야 하고, 제 3자 서비스에 전달할 알림 페이로드를 만들어 낼 수 있어야 한다
5-3) 제 3자 제공 서비스 : 사용자에게 실제로 알림을 전달하는 역할. 확장성이 중요하다. 쉽게 새로운 서비스를 통합하거나 기존 서비스를 제거할 수 있어야 한다
* 발생가능한 문제
1. SPOF : 알림 서비스의 서버가 하나밖에 없어, 그 서버의 장애 발생 시 전체 서비스 장애로 이어진다
2. 규모 확장성 : 푸시 알림에 관계된 모든 것을 한 대의 서버에서 처리하기 때문에 추후 확장이 어렵다
6) 최종 설계

- 데이터베이스와 캐시를 알림 시스템의 주 서버에서 분리한다
- 알림 서버를 증설하고 자동으로 수평 규모 확장이 가능하도록 한다
- 메시지 큐를 이용한 시스템 컴포넌트 사이 강한 결합을 끊는다
2. 구글 드라이브 설계
2.1) 요구사항
- 파일 추가
- 파일 다운로드
- 여러 단말에 파일 동기화
- 파일 갱신 이력 조회
- 파일 공유
- 파일 편집 & 삭제 알림 표시
2.2) 구현 API
(1) 파일 업로드 API
- 단순 업로드 : 파일 크기가 작을 때 사용
- 이어 올리기 : 파일 크기가 크거나 네트워크 단절이 생길 경우 사용한다
(2) 파일 다운로드 API
ex) POST https://api.example.com/files/download --data '{"path" : "/recipes/soup/best_soup.txt"}'
2.3) 한 대 서버 제약 극복
파일시스템의 여유 공간이 없다면 ~ 데이터를 샤딩하여 여러 서버에 나눠 저장할 수 있다

여유 공간이 없을 때마다 매번 샤딩을 하는 것은 번거롭다. ~ 알려진 서비스를 사용 : AWS S3
2.4) 고민 포인트
(1) 로드 밸런서
- 네트워크 트래픽을 분산하기 위해 사용
- 로드 밸런서는 트래픽을 고르게 분산할 뿐 아니라 장애가 발생하면 자동으로 해당 서버를 우회한다
(2) 웹 서버
- 로드 밸런서를 추가하고 나면 더 많은 웹 서버를 쉽게 추가할 수 있어 트래픽이 증가해도 쉽게 대응이 가능하다
(3) 메타 데이터 데이터베이스
- 데이터베이스 파일 저장 서버에서 분리해 SPOF를 회피
- 사용자 이름, 파일 이름, 업로드 날짜
(4) 파일 저장소
- S3 파일 저장소로 사용하고 가용성과 데이터 손실을 막기 위해 두 개 이상의 지역에 데이터를 다중화
2.5) 동기화 충돌
~ 두 명 이상의 사용자가 같은 파일이나 폴더를 동시에 업데이트할 경우
-> 버전으로 해결
-> 먼저 처리되는 변경은 성공한 것으로 보고, 나중에 처리되는 변경은 충돌이 발생한 것으로 표시 ~ 두 가지 버전을 합칠 지 대체할 지 결정
2.5) 설계

(1) 사용자 단말 : 웹 브라우저 등
(2) 블록 저장소 서버
- 파일 블록을 클라우드 저장소에 업로드하는 서버, 클라우드 환경에서 데이터 파일을 저장하는 기술
- 이 저장소는 파일을 여러 개의 블록으로 나눠 저장하며 각 블록에는 고유한 해시값이 할당
- 고유한 해시값은 메타데이터 DB에 저장
- 각 블록은 독립 객체로 취급되며, S3에 보관된다
- 파일을 재구성하려면 블록들은 원래 순서대로 합쳐야 한다
(3) 클라우드 저장소
- 파일은 블록 단위로 나눠져 S3에 보관된다
(4) 아카이빙 저장소
- 비활성 데이터를 저장하기 위한 시스템
(5) 로드 밸런서
- 요청을 모든 API 서버에 고르게 분산
(6) API 서버
- 사용자 인증, 사용자 프로파일 관리, 파일 메타데이터 갱신 등
(7) 메타데이터 DB
- 사용자, 파일, 블록, 버전 등의 메타데이터 정보를 관리
- 실제 파일은 클라우드에 보관, 해당 DB는 메타데이터만 저장
(8) 메타데이터 캐시
- 성능을 높히기 위해 자주 쓰이는 메타데이터는 캐시한다
(9) 알림 서비스
- 특정 이벤트가 발생했음을 클라이언트에게 알리는데 쓰이는 시스템
- 예를 들어 클라이언트에게 파일이 추가되거나, 편집 삭제되었음을 알림
(10) 오프라인 사용자 백업 큐
- 클라이언트가 접속 중이 아니라서 파일의 최신 상태를 확인할 수 없을 때, 해당 정보를 이 큐에 둬 나중에 클라이언트가 접속했을 때 동기화될 수 있도록 한다
2.6) 블록 저장소 서버
정기적으로 갱신되는 큰 파일들은 업데이트가 일어날 때마다 전체 파일을 서버로 보내면 네트워크 대역폭을 많이 잡아먹는다. 이를 최적화하는 방법
- 델타 동기화 : 파일이 수정되면 전체 파일 대신 수정이 일어난 블록만 동기화한다
- 압축 : 블록 단위로 압축해 데이터 사이즈를 줄인다
델타 동기화는 그림처럼 갱신된 부분만 S3에 업로드하면 된다

2.7 알림 서비스
(1) 알림 서비스
- 이벤트 데이터를 클라이언트들로 보내는 서비스
- 알림 서비스 구현으로 롱 폴링, 웹 소켓 방식을 채택할 수 있다
(2) 롱 폴링
- 드롭박스
- 각 클라이언트는 알림 서버와 롱 폴링용 연결을 유지
- 특정 파일에 대한 변경 감지 -> Connection 끊음
- 이 때 클라이언트는 반드시 메타데이터 서버와 연결해 파일의 최신 내역을 다운로드한다
- 다운로드 작업이 끝나거나 timeout이 되면 새 요청을 보내 롱 폴링 연결을 복원 및 유지
(3) 웹 소켓
- 클라이언트 <-> 서버, 클라이언트 간 지속 통신 채널 제공
2.8) 저장소 공간 절약
(1) 중복 제거
- 두 블록이 같은 블록인지 해시 값을 비교해 판단한다
- 예시) MD5와 같은 해시 함수 사용해 해시 값 비교
(2) 지능적 백업 전략 도입
- 파일 버전 개수에 상한을 둔다 -> 상한에 도달하면 제일 오래된 버전은 버린다
- 중요한 버전만 보관한다 -> 자주 수정되는 파일은 불필요한 버전을 많이 생성한다
(3) 자주 쓰이지 않는 데이터는 아카이빙 저장소로 옮긴다
- S3 글래시어 같은 아카이빙 저장소 사용
'개발공부 > 원티드 챌린지 정리' 카테고리의 다른 글
| 8월 백엔드 챌린지 : 도커 프로 (2) (0) | 2023.10.02 |
|---|---|
| 8월 백엔드 챌린지 : 도커 프로 (1) (0) | 2023.09.21 |
| 7월 백엔드 챌린지 3. 사용자 수에 따른 규모를 확장하는 방법 2 (0) | 2023.08.06 |
| 7월 백엔드 챌린지 2. 사용자 수에 따른 규모를 확장하는 방법 (0) | 2023.08.01 |
| 7월 백엔드 챌린지 1. 기술 면접에서 시스템 설계 문제가 가지는 의미 (0) | 2023.07.31 |